🏃TL;DR:
We will explore how to create, build and deploy every component
behind this Bikes recommendation website: 🔗demo
📧 Found an error or have a question? write to me or leave a comment
🔗 Article posted on medium also
- 🎯 Goal
- ℹ Foreword
- 🗺️ Roadmap
- 🚵♀️ Garrascobike
- 🎌 Other languages
- 💭 Final Thoughts
🎯 Goal Link to heading
High-level Link to heading
The idea behind this project is to test the opportunity to build a recommendation system using public data, unsupervised machine learning (ML) models and only free resources.
To achieve this we will:
- Leverage Reddit to gather the data
- Spacy transformers as ML framework
- Google Colab to run the ML model, Heroku to host the back-end, GitHub pages to host the front-end
Implementation Link to heading
Garrascobike is a mountain bike (MTB) recommendation system.
In other words, you could choose a bike brand or model that you like and then the system will suggest 3 bikes considered interesting and related to your chosen bike.
The idea behind the recommendation system is: when people talk about some Bikes on the same subreddit thread those bikes should be related in some way. So we could extract the Bike’s names and/or brands from one thread’s comments and intersect that information with other Reddit threads with similar bikes.
ℹ Foreword Link to heading
The goal of this guide is to chase all the aspects involved in the creation of a Web App that serves a simple recommendation system, trying to keep the complexity level lower as possible.
So the technical level of this experiment won’t be too deep and we don’t follow industrial-level best practices, nevertheless, this is the guide I would like to have one year ago before starting a simple project: create a WebApp with an ML model at is core.
🗺️ Roadmap Link to heading
What we will do could be summarized in the following steps:
- Download text comments from Reddit 🐍
- Extract interesting entities from the comments 🐍🤖
- Create a simple recommendation system model 🐍🤖
- Deploy the model on a back-end 🐍
- Create a front-end that expose the model predictions 🌐
🐍 = blocks that use Python
🤖 = blocks with Machine Learning topics involved
🌐 = blocks that use HTML, CSS & Javascript
🚵♀️ Garrascobike Link to heading
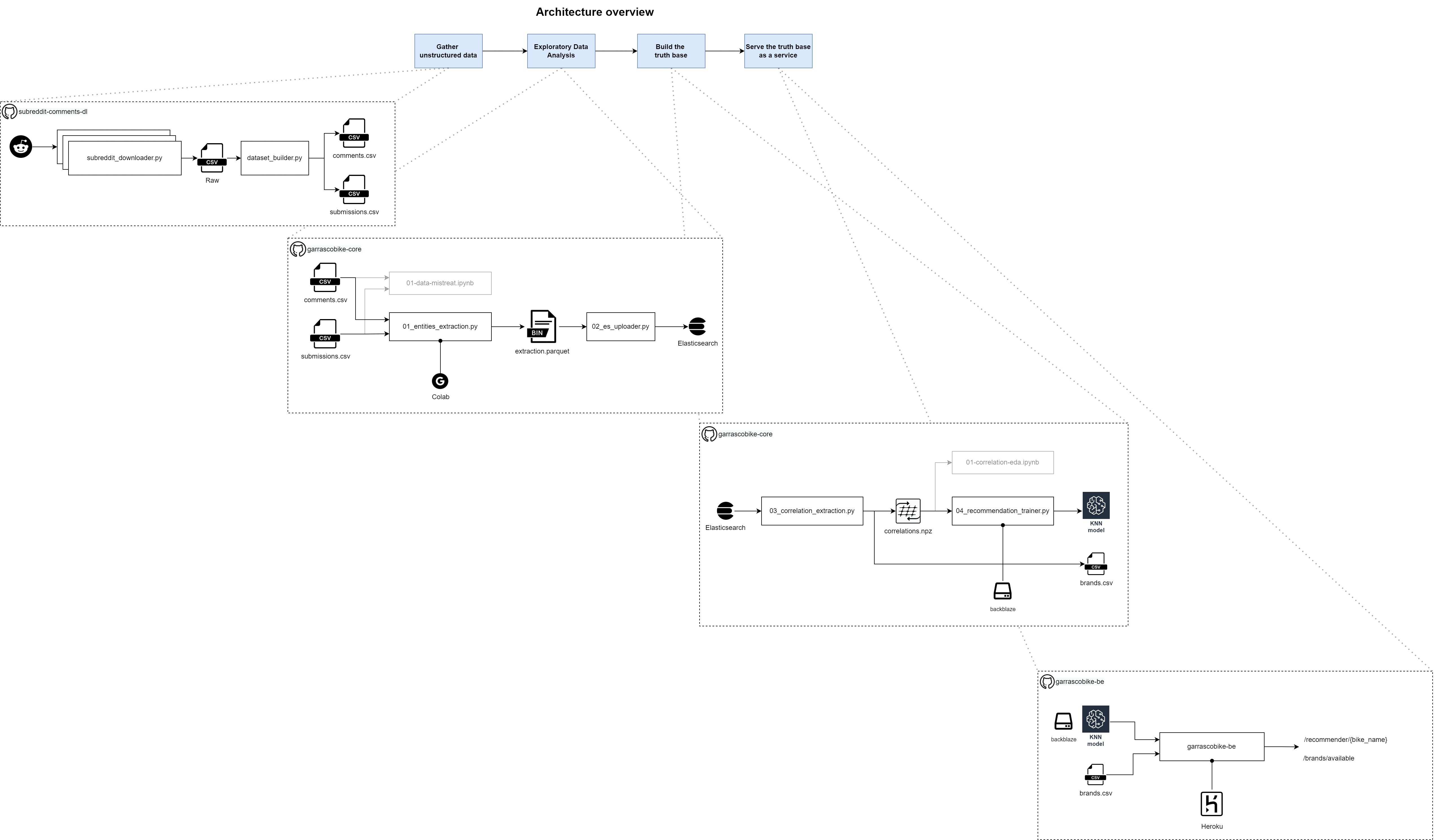
Project architecture overview
The project is structured in five major sections: scraping, entities extraction, ML train, back-end, front-end (and they coincide with the five chapters of this post).
On the above image, the first four sections (front-end is excluded) are reported with their dependencies and where necessary the platform where the code should be executed.
Let’s dive deep into each component.
1. Download text comments from Reddit 🐍 Link to heading
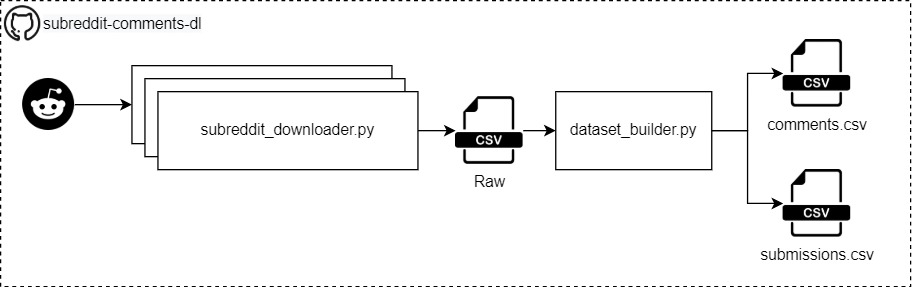
The architecture of the Reddit scraper
Intro Link to heading
First of all: we need the data and Reddit is an amazing social network where people talk about any topic. Moreover, Reddit expose some API that python packages like praw could use to scrape the data.
Prerequisites Link to heading
- We need to choose some subreddits that talk about the topic on which we would create the recommendation system
- In Garrascobike we want to build a Mountain Bike recommendation system, so we need subreddits that talk about those bikes.
- The subreddits selected for this PoC project are:
How to Link to heading
- 👨💻Code to use hosted on Github: subreddit-comments-dl
- Follow this guide to download Reddit comments:
- More information is also on my blog:
Outcome Link to heading
- Two CSV files with all the information about the subreddit comments.
- We will create two CSV files, if you are not familiar with Reddit could be useful to read this little glossary
- comments.csv
- Contain all the comments with related information, e.g. the comment’s text, the creation date, the subreddit and thread where the comment was written
- submissions.csv
- Contain all the information about the submissions: a submission is a post that appears in each subreddit
- comments.csv
2. Extract interesting entities from the comments 🐍🤖 Link to heading
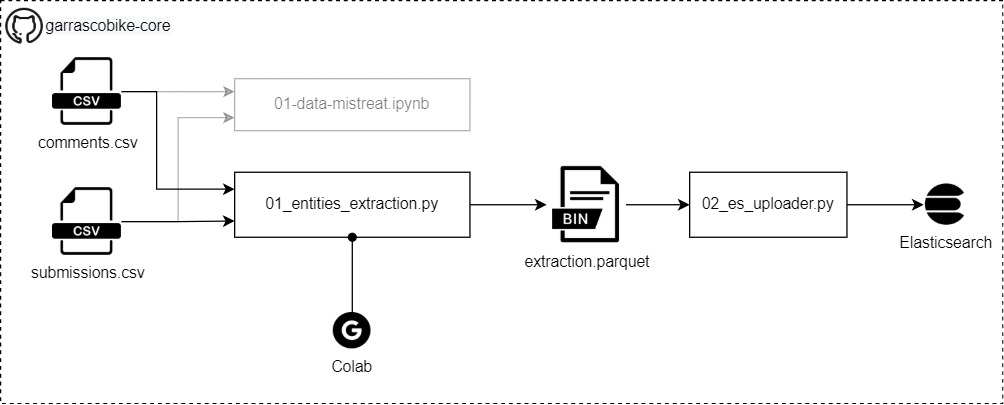
The architecture of the Entities extractor
Intro Link to heading
- Entities are words or sections of a text that belong to some pre-defined “family”
- e.g. from a text like “I have a 2019 Enduro” we would like to extract something like “2019” is a DATE and “Enduro” is a PRODUCT
- The entities extraction is related to an ML task called Named Entity Recognition (NER), for more examples see the official Spacy webpage
- So this block get the Reddit comments and will extract the Bikes names contained within them (extraction.parquet)
- That information will be uploaded to an Elasticsearch instance
Prerequisites Link to heading
- The comments extracted from the desired subreddit
- How many comments?
- More comments are directly proportional to better performances
- For this project, we have downloaded 800.000 comments from 103.159 submissions
How to Link to heading
- 👨💻Code to use hosted on Github: garrascobike-core
- Extract the entities
- Steps
- Clone the repository https://github.com/pistocop/garrascobike-core
- Copy the scraped data under
/data/01_subreddit_extractions/ - Run the extraction with the script
/garrascobike/01_entities_extraction.py- Under the hood the script will use Spacy NER system with a spacy-transformers ML model
- 💡Tip: use this Colab Notebook to run the above tasks
- Because the process will use a machine-learning model it’s suggested to execute the code on a machine with a GPU.
- If you aren’t rich like me there is a big chance that you haven’t a powerful GPU for ML tasks, so use the above notebook and leverage the Google GPU’s for free 💘
- Steps
- Load on Elasticsearch
- What and why
- Elasticsearch is a documental NoSQL database that could store data even if we don’t know the data structure
- Why we should use Elasticsearch (ES)?
- It wasn’t mandatory to use this technology if we remain in the POC zone, and a python script could be enough to do the same job required for this project.
- However, use ES pledge us with the opportunity to be ready if we go out of the POC and/or we want to reuse the data in different ways for other projects.
- ES was used during the first data scouting phase, when wasn’t clear which data the ML model has extracted and if it’s possible to shape that information to our requirements
- Using ES on this scouting phase was very helpful to data discovery and express queries like “how many threads exist with at least 1 product entity”, “get all the entities typer” or “list all the PRODUCT entities”
- Last but not least, I was preparing for the ES Certified Engineer exam so I was more comfortable with this framework and introducing it here was a good way to practice with it
- It wasn’t mandatory to use this technology if we remain in the POC zone, and a python script could be enough to do the same job required for this project.
- Run the Elasticsearch service locally
- Install Docker
- Following this guide to run a mini-cluster locally, the
01_single-nodecluster is suggested
- Load the data
Run the script
/garrascobike/02_es_uploader.pyscript providing the parquet file and the ES endpoints# folder garrascobike-core $ python garrascobike/02_es_uploader.py --es_index my_index \ --es_host http://localhost \ --es_port 9200 \ --input_file ./data/02_entities_extractions/extraction.parquet
- What and why
3. Create a simple recommendation system model 🐍🤖 Link to heading
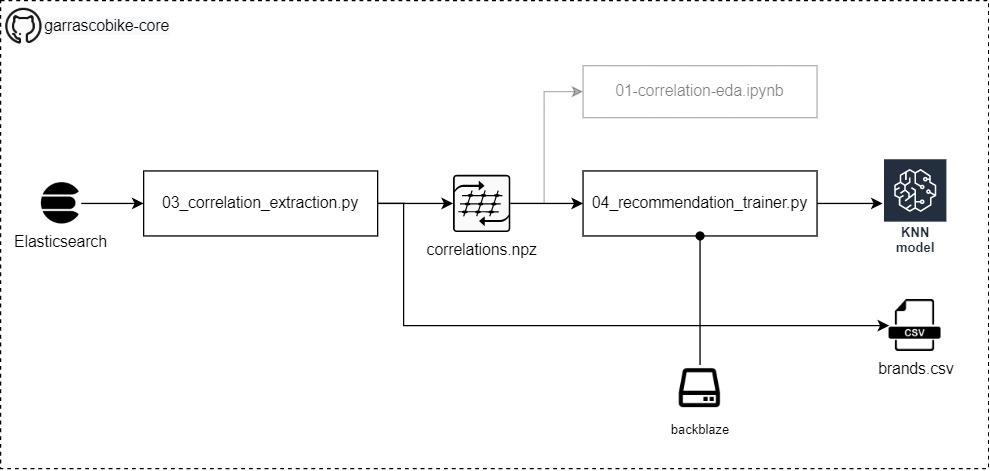
The architecture of the Recommendation builder
Intro Link to heading
- The parsed comments are now associated with text snippets named product from the entities extraction process
- After a look at those snippets, we could see that the product entities here are the Bikes names and brands that users on subreddits talk about
- 🦂 Of course there is also noise labelled as product, e.g. “canyon/giant” is a snippet that contains two brands and should not be included and/or split into two entities “canyon” and “giant”. Moreover, “12speed” isn’t a brand but the number of gears of the bike.
- For this toy project, we don’t care about the noise, so the predictions may result in suggesting bikes that don’t exist. In a real-world scenario, we should apply some revision to those products, e.g. search each brand on an images search engine and see if a bike picture is returned.
- Nevertheless, some brands cleaning and filtering is actually performed - code link
- The recommendation system will be built around the intersection of bikes brands and the comments threads to which the comments belong
- We will create a semifinished product: correlations.npz (new code version store a file named presences.csv), this file contain the product entities found for each subreddit thread
- In the last step, 04_recommendation_trainer.py will train ad store an AI model based on the KNN algorithm able to make the bikes recommendations process
- More about this process could be found in those good articles:
- Finally, we will upload by hand (no automatic script provided) the files create by 04_recommendation_trainer.py
- Use backblaze.com is suggested and supported by the next chapter section, it provides 10 GB of storage for free
Prerequisites Link to heading
- An ES instance running with the products entities extracted
- An account on backblaze.com
How to Link to heading
👨💻Code to use hosted on Github: https://github.com/pistocop/garrascobike-core
Run the 03_correlation_extraction.py script, parameters:
- es_host: the Elasticsearch instance address
- es_port: the Elasticsearch instance port
- es_index_list: the Elasticsearch indexes names. They could be more than one because it’s possible to join more entities extraction. However for this guide we could use only one parameter: my_index.
$ python garrascobike/03_correlation_extraction.py --es_host localhost \ --es_port 9200 \ --es_index_list my_index opt_my_2nd_indexRun the 04_recommendation_trainer.py script, parameters:
- presence_data_path: the path to the file created by 03_correlation_extraction.py
- ml_model: the model to use to build the recommendation system, only knn is currently available
- output_path: where to save the recommendation system model files, those files should be then uploaded on backblaze
$ python garrascobike/04_recommendation_trainer.py --presence_data_path ./data/03_correlation_data/presence_dataset/20210331124802/presences.csv \ --output_path ./data/04_recommendation_models/knn/
Outcome Link to heading
- The recommendation system model trained to predict bikes suggestion from one bike name provided
- All the recommendation model files should be uploaded on Backblaze
4. Deploy the model on a back-end 🐍 Link to heading
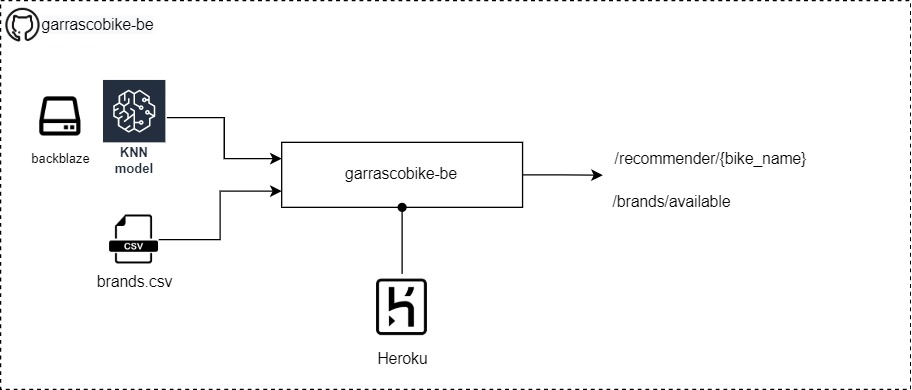
The architecture of the Backend
Intro Link to heading
- To make the recommendation we need a machine that runs the prediction model
- We will wrap the model inside a back-end that:
- Is in Python and use FastAPI framework
- Run on heroku free Dyno as the hardware provider
- Run for 30m and then go to sleep mode
- If it’s in the sleep node, need ~1m to wake up and be ready to use
- The back-end will expose those API:
/recommender/{bike_name}that take a bike name and return 3 bikes suggested/brands/availablethat return the list of supported bike names/healththat returns a timestamp and will be used to check if the back-end is up and in running state
Prerequisites Link to heading
- We need the list of bikes that the recommendation system model can manage:
brands.csv - The recommendation model that the back-end will use to make the predictions
How to Link to heading
- 👨💻Code to use hosted on Github: https://github.com/pistocop/garrascobike-be
- Set the correct credentials and path according to your backblaze account:
- To set the Backblaze bucket name and path modify the file at:
/garrascobike_be/ml_model/hosted-model-info.json - To set the Backblaze connection credentials modify and rename to
.envthe file:/garrascobike_be/.env_example
- To set the Backblaze bucket name and path modify the file at:
- Create an account on heroku and publish the back-end: follow this guide for more detailed information:
Outcome Link to heading
A back-end up and running on Heroku, you could get the API URL from the “open app” button inside the Heroku webpage
- The back-end openAPI specification could be found under
https://<heroku-app-url>/docsand will look like this:
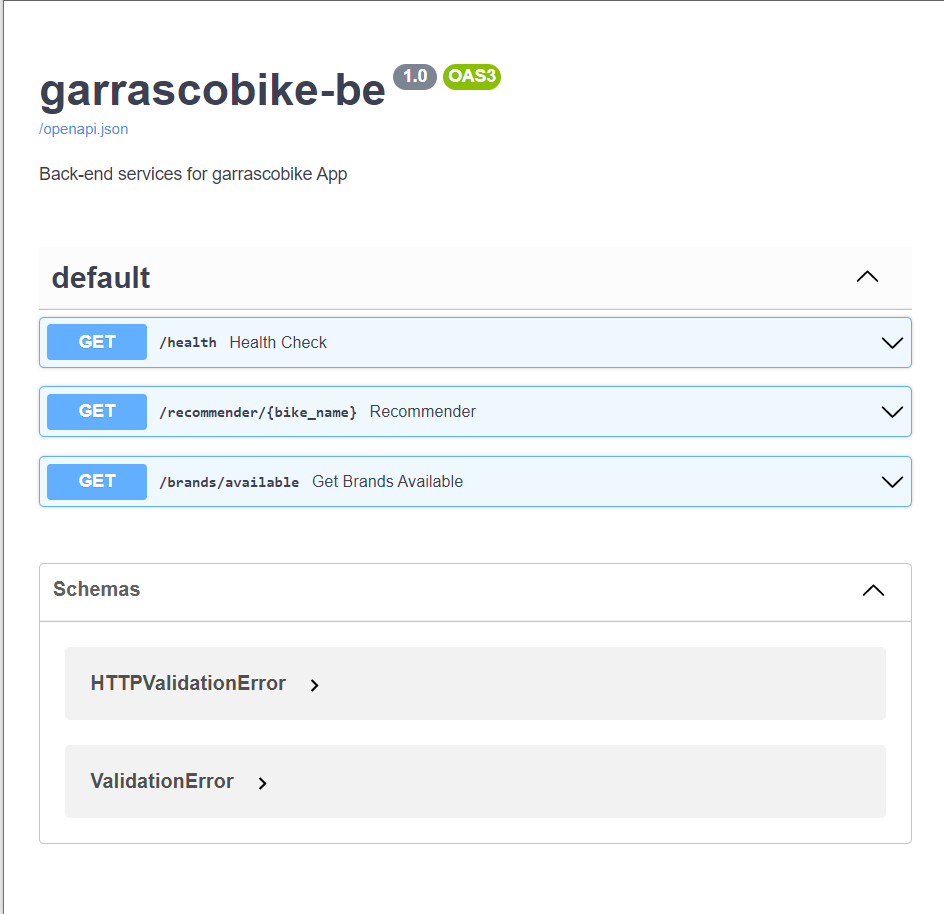
Garrascobike back-end OpenAPI webpage
- Note: you may need to wait ~1m before seeing this OpenAPI specification
- The back-end openAPI specification could be found under
5. Create a front-end that expose the model predictions 🌐 Link to heading
Intro Link to heading
- We need a website that the user could use to choose the desired bike and receive the suggestions
- The website must use the API exposed by the back-end
- However, for this reason, the FE need to show some kind of “wait disclaimer” while Heroku wake up the App
- The FE should also provide succinctly the list of bikes that the user could choose from
- We will build an autocomplete text field using the amazing autoComplete.js framework
- We will create a static website with HTML, CSS & JS
- The website is then hosted for free on GitHub Pages
Prerequisites Link to heading
- The Garrascobike back-end up and running online
- The URL of the back-end
live-serverprogram to run the website locally - npm
How to Link to heading
- 👨💻Code to use hosted on Github: https://github.com/pistocop/garrascobike-fe
- Steps to set up a new front-end
- Fork the project
- Replace this line with your back-end URL
- Commit the changes
- Follow this guide to enable the GitHub pages service on your repository (note: the repo must be public!)
- Follow the link generated by the GitHub interface
- Enjoy your new front-end!
Outcome Link to heading
- Demo of the website: https://pistocop.github.io/garrascobike-fe/
- The website you will see should resemble like this:

Garrascobike-fe banner of “wait heroku woke up the back-end”

Garrascobike-fe main page
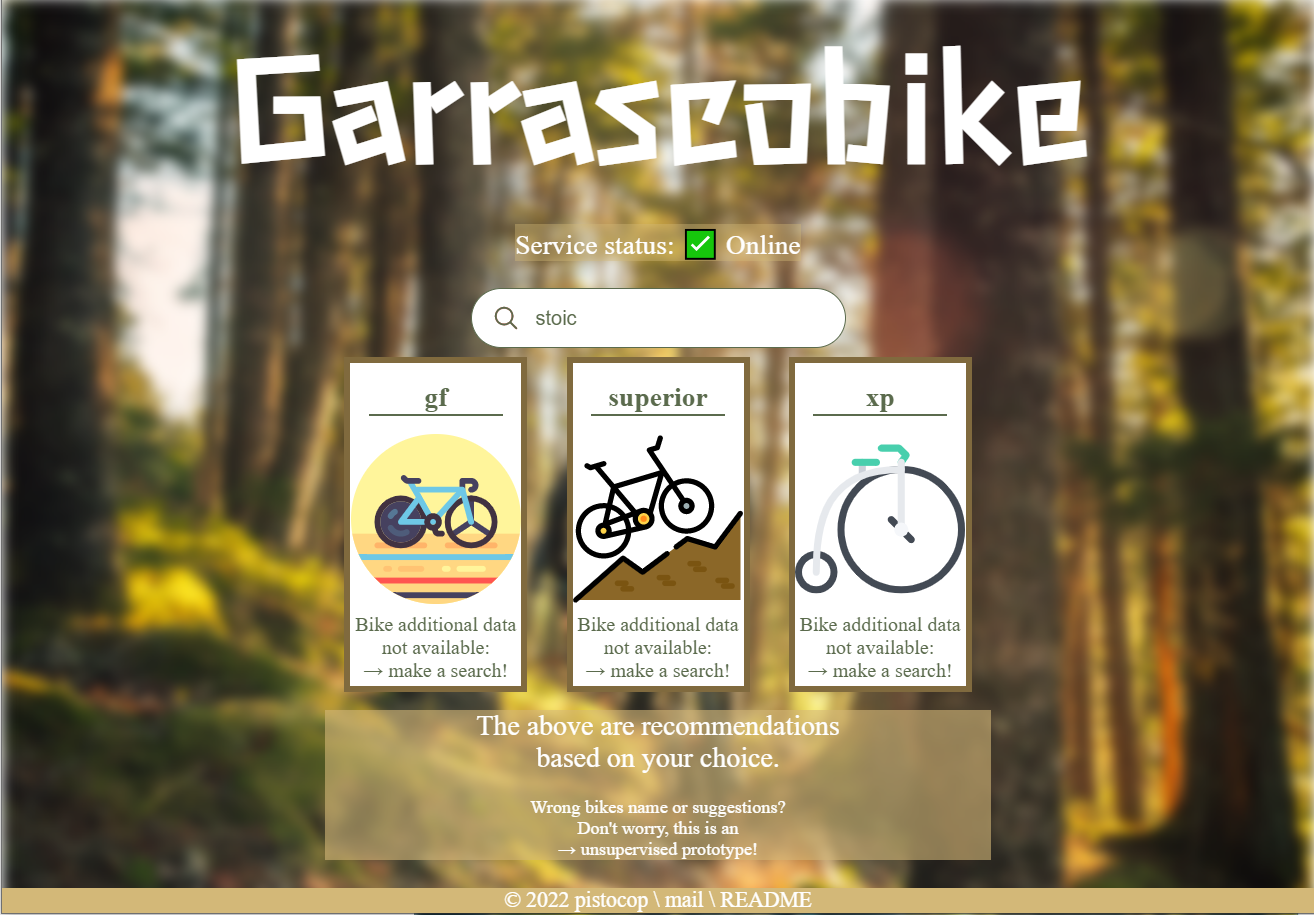
Garrascobike-fe example of a suggestion request, with placeholder images for each bike predicted
🎌 Other languages Link to heading
- All the project is built and work for English Subreddits
- Other languages could be supported, the only section that requires a change is the spacy model in the https://github.com/pistocop/garrascobike-core entities extraction task
- Spacy transformers models of different languages could be found here: language support
💭 Final Thoughts Link to heading
We have just seen how to build a recommendation system from the scraping process to a WebApp.
All the data are scraped from Reddit and processed with unsupervised ML models (Spacy), using the Google Colab platform. This has saved us a lot of work and supplied a straightforward path that could be automatized also.
Finally, a back-end free hosted on Heruko and a front-end free hosted on GitHub pages complete the project thanks to a web app page.
From here, a lot of work could be done to refine each of the components, e.g. if we want to move from a POC project like this to production and more serious system we should:
- Filter and remove all the entities extracted that aren’t bikes
- Scrape and process more data
- Build and test different parameters or families for the recommendation system
As final, I want to say that it was nice to build this project, I haven’t experience with the front-end world and the simple website is made after following theodinproject.com free course.
And now, after completing every component and the website is up and running, I must admit that I feel satisfied, hope you’ve enjoyed the journey!